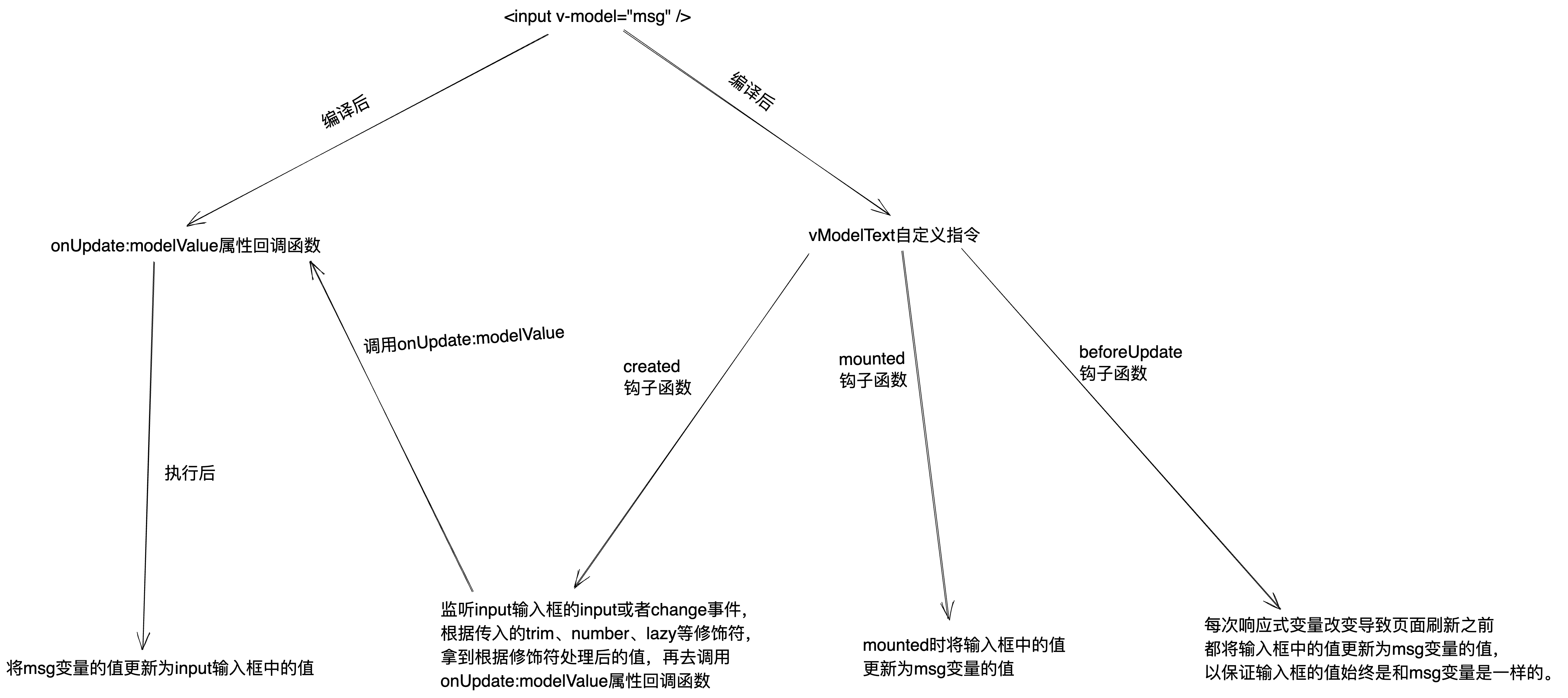
多项式回归
- 解决线性回归的准备性不足问题(线性回归只能是直线,多项式回归引入多项式可以是曲线)
- 通过对预测值进行多项式转换, 使得回归模型可以是非线性的
- 多项式回归的优点是可以处理非线性的数据
- 多项式回归的缺点是它对数据进行了多项式转换
polynomial = PolynomialFeatures(degree=2)
poly_linear_model = linear_model.LinearRegression()
X_train_transformed = polynomial.fit_transform(X_train)
poly_linear_model.fit(X_train_transformed, y_train)
X_test_transformed = polynomial.fit_transform(X_test)
y_test_poly_pred = poly_linear_model.predict(X_test_transformed)
print(y_test_poly_pred)
决策树回归
- 集成学习(Ensemble Learning) 旨在通过组合多个基本模型(弱学习器)的预测创建一个强学习器(强学习器)
- Boosting(提升) 和 Bagging(袋装) 都是集成学习的思想
- Bagging(袋装) 原始数据集随机采样, 然后将采样的数据集分别训练多个决策树模型, 最后将这些决策树模型的预测结果进行投票(投票:分类, 回归:平均), 得到最终的预测结果
- Boosting(提升) 通过迭代的方式, 训练多个决策树模型, 最后将这些决策树模型的预测结果进行加权平均, 得到最终的预测结果
- bagging: 适用于高方差、低偏差的数据集 (random forest 随机森林)
- boosting: 适用于高偏差、低方差的数据集 (AdaBoost 自适应增强)
- 偏差: 预测结果的准确性
- 方差: 预测结果的离散程度
决策树回归 decision tree regression
from sklearn.tree import DecisionTreeRegressor
dt_regressor = DecisionTreeRegressor(max_depth=4)
dt_regressor.fit(X_train, y_train)
y_pred_dt = dt_regressor.predict(X_test)
mse = mean_squared_error(y_test, y_pred_dt)
evs = explained_variance_score(y_test, y_pred_dt)
print("#### Decision Tree performance ####")
print("Mean squared error (均方误差/平均平方误差 (越小越好)) = ", round(mse, 2))
print("Explained variance score (解释方差分 (0-1) 1 接近表示解释能力越好) =", round(evs, 2))
def plot_feature_importances(feature_importances, title, feature_names):
feature_importances = 100.0 * (feature_importances / max(feature_importances))
index_sorted = np.flipud(np.argsort(feature_importances))
pos = np.arange(index_sorted.shape[0]) + 0.5
plt.figure()
plt.bar(pos, feature_importances[index_sorted], align='center')
print(pos, index_sorted, feature_importances)
plt.xticks(pos, [feature_names[i] for i in index_sorted])
plt.ylabel('Relative Importance')
plt.title(title)
plt.show()
plot_feature_importances(dt_regressor.feature_importances_, 'Decision Tree regressor', data_columns)
自适应决策树回归 adaboost regressor
from sklearn.ensemble import AdaBoostRegressor
ab_regressor = AdaBoostRegressor(DecisionTreeRegressor(max_depth=4), n_estimators=400, random_state=7)
ab_regressor.fit(X_train, y_train)
y_pred_ab = ab_regressor.predict(X_test)
mse = mean_squared_error(y_test, y_pred_ab)
evs = explained_variance_score(y_test, y_pred_ab)
print("#### AdaBoost performance ####")
print("Mean squared error (均方误差/平均平方误差 (越小越好)) = ", round(mse, 2))
print("Explained variance score (解释方差分 (0-1) 1 接近表示解释能力越好) =", round(evs, 2))
def plot_feature_importances(feature_importances, title, feature_names):
feature_importances = 100.0 * (feature_importances / max(feature_importances))
index_sorted = np.flipud(np.argsort(feature_importances))
pos = np.arange(index_sorted.shape[0]) + 0.5
plt.figure()
plt.bar(pos, feature_importances[index_sorted], align='center')
print(pos, index_sorted, feature_importances)
plt.xticks(pos, [feature_names[i] for i in index_sorted])
plt.ylabel('Relative Importance')
plt.title(title)
plt.show()
plot_feature_importances(ab_regressor.feature_importances_, 'AdaBoost regressor', data_columns)
随机森林回归 random forest regressor
from sklearn.ensemble import RandomForestRegressor
rf_regressor = RandomForestRegressor(n_estimators=1000, max_depth=4, min_samples_split=2)
rf_regressor.fit(X_train, y_train)
y_pred_rf = rf_regressor.predict(X_test)
mse = mean_squared_error(y_test, y_pred_rf)
evs = explained_variance_score(y_test, y_pred_rf)
print("#### Random Forest Regressor performance ####")
print("Mean squared error (均方误差/平均平方误差 (越小越好)) = ", round(mse, 2))
print("Explained variance score (解释方差分 (0-1) 1 接近表示解释能力越好) =", round(evs, 2))
def plot_feature_importances(feature_importances, title, feature_names):
feature_importances = 100.0 * (feature_importances / max(feature_importances))
index_sorted = np.flipud(np.argsort(feature_importances))
pos = np.arange(index_sorted.shape[0]) + 0.5
plt.figure()
plt.bar(pos, feature_importances[index_sorted], align='center')
print(pos, index_sorted, feature_importances)
plt.xticks(pos, [feature_names[i] for i in index_sorted])
plt.ylabel('Relative Importance')
plt.title(title)
plt.show()
plot_feature_importances(rf_regressor.feature_importances_, 'random forest regressor', data_columns)